Data Output¶
Similarly important to data input is data output. Using a data output module allows you to restructure and rename computed output and to spatially differentiate relevant output files from the temporary computed intermediate files in the working directory. Nipype provides the following modules to handle data stream output:
DataSink
JSONFileSink
MySQLSink
SQLiteSink
XNATSink
This tutorial covers only DataSink. For the rest, see the section interfaces.io on the official homepage.
DataSink¶
A workflow working directory is like a cache. It contains not only the outputs of various processing stages, it also contains various extraneous information such as execution reports, hashfiles determining the input state of processes. All of this is embedded in a hierarchical structure that reflects the iterables that have been used in the workflow. This makes navigating the working directory a not so pleasant experience. And typically the user is interested in preserving only a small percentage of these outputs. The DataSink interface can be used to extract components from this cache and store it at a different location. For XNAT-based storage, see XNATSink.
Let's assume we have the following workflow.
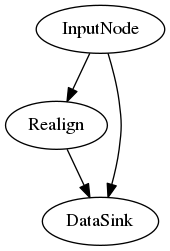
The following code segment defines the DataSink node and sets the base_directory in which all outputs will be stored. The container input creates a subdirectory within the base_directory. If you are iterating a workflow over subjects, it may be useful to save it within a folder with the subject id.
datasink = pe.Node(nio.DataSink(), name='sinker')
datasink.inputs.base_directory = '/path/to/output'
workflow.connect(inputnode, 'subject_id', datasink, 'container')
If we wanted to save the realigned files and the realignment parameters to the same place the most intuitive option would be:
workflow.connect(realigner, 'realigned_files', datasink, 'motion')
workflow.connect(realigner, 'realignment_parameters', datasink, 'motion')
However, this will not work as only one connection is allowed per input port. So we need to create a second port. We can store the files in a separate folder.
workflow.connect(realigner, 'realigned_files', datasink, 'motion')
workflow.connect(realigner, 'realignment_parameters', datasink, 'motion.par')
The period (.) indicates that a subfolder called par should be created. But if we wanted to store it in the same folder as the realigned files, we would use the .@ syntax. The @ tells the DataSink interface to not create the subfolder. This will allow us to create different named input ports for DataSink and allow the user to store the files in the same folder.
workflow.connect(realigner, 'realigned_files', datasink, 'motion')
workflow.connect(realigner, 'realignment_parameters', datasink, 'motion.@par')
The syntax for the input port of DataSink takes the following form:
string[[.[@]]string[[.[@]]string] ...]
where parts between paired [] are optional.Parameterization¶
As discussed in Iterables, one can run a workflow iterating over various inputs using the iterables attribute of nodes. This means that a given workflow can have multiple outputs depending on how many iterables are there. Iterables create working directory subfolders such as _iterable_name_value. The parameterization input parameter controls whether the data stored using DataSink is in a folder structure that contains this iterable information or not. It is generally recommended to set this to True when using multiple nested iterables.
Substitutions¶
The substitutions and regexp_substitutions inputs allow users to modify the output destination path and name of a file. Substitutions are a list of 2-tuples and are carried out in the order in which they were entered. Assuming that the output path of a file is:
/root/container/_variable_1/file_subject_realigned.nii
we can use substitutions to clean up the output path.
datasink.inputs.substitutions = [('_variable', 'variable'),
('file_subject_', '')]
This will rewrite the file as:
/root/container/variable_1/realigned.nii
First, let's create a SelectFiles node. For an explanation of this step, see the Data Input tutorial.
from nipype import SelectFiles, Node
# Create SelectFiles node
templates={'func': '{subject}/{session}/func/{subject}_{session}_task-fingerfootlips_bold.nii.gz'}
sf = Node(SelectFiles(templates),
name='selectfiles')
sf.inputs.base_directory = '/data/ds000114'
sf.inputs.subject = 'sub-01'
sf.inputs.session = 'ses-test'
Second, let's create the motion correction and smoothing node. For an explanation about this step, see the Nodes and Interfaces tutorial.
from nipype.interfaces.fsl import MCFLIRT, IsotropicSmooth
# Create Motion Correction Node
mcflirt = Node(MCFLIRT(mean_vol=True,
save_plots=True),
name='mcflirt')
# Create Smoothing node
smooth = Node(IsotropicSmooth(fwhm=4),
name='smooth')
Third, let's create the workflow that will contain those three nodes. For an explanation about this step, see the Workflow tutorial.
from nipype import Workflow
from os.path import abspath
# Create a preprocessing workflow
wf = Workflow(name="preprocWF")
wf.base_dir = '/output/working_dir'
# Connect the three nodes to each other
wf.connect([(sf, mcflirt, [("func", "in_file")]),
(mcflirt, smooth, [("out_file", "in_file")])])
Now that everything is set up, let's run the preprocessing workflow.
wf.run()
After the execution of the workflow we have all the data hidden in the working directory 'working_dir'. Let's take a closer look at the content of this folder:
! tree /output/working_dir/preprocWF
As we can see, there is way too much content that we might not really care about. To relocate and rename all the files that are relevant to you, you can use DataSink.
How to use DataSink¶
DataSink is Nipype's standard output module to restructure your output files. It allows you to relocate and rename files that you deem relevant.
Based on the preprocessing pipeline above, let's say we want to keep the smoothed functional images as well as the motion correction parameters. To do this, we first need to create the DataSink object.
from nipype.interfaces.io import DataSink
# Create DataSink object
sinker = Node(DataSink(), name='sinker')
# Name of the output folder
sinker.inputs.base_directory = '/output/working_dir/preprocWF_output'
# Connect DataSink with the relevant nodes
wf.connect([(smooth, sinker, [('out_file', 'in_file')]),
(mcflirt, sinker, [('mean_img', 'mean_img'),
('par_file', 'par_file')]),
])
wf.run()
Let's take a look at the output folder:
! tree /output/working_dir/preprocWF_output
This looks nice. It is what we asked it to do. But having a specific output folder for each individual output file might be suboptimal. So let's change the code above to save the output in one folder, which we will call 'preproc'.
For this we can use the same code as above. We only have to change the connection part:
wf.connect([(smooth, sinker, [('out_file', 'preproc.@in_file')]),
(mcflirt, sinker, [('mean_img', 'preproc.@mean_img'),
('par_file', 'preproc.@par_file')]),
])
wf.run()
Let's take a look at the new output folder structure:
! tree /output/working_dir/preprocWF_output
This is already much better. But what if you want to rename the output files to represent something a bit more readable. For this DataSink has the substitution input field.
For example, let's assume we want to get rid of the string 'task-fingerfootlips' and 'bold_mcf' and that we want to rename the mean file, as well as adapt the file ending of the motion parameter file:
# Define substitution strings
substitutions = [('_task-fingerfootlips', ''),
("_ses-test", ""),
('_bold_mcf', ''),
('.nii.gz_mean_reg', '_mean'),
('.nii.gz.par', '.par')]
# Feed the substitution strings to the DataSink node
sinker.inputs.substitutions = substitutions
# Run the workflow again with the substitutions in place
wf.run()
Now, let's take a final look at the output folder:
! tree /output/working_dir/preprocWF_output
Cool, much clearer filenames!
Exercise 1¶
Create a simple workflow for skullstriping with FSL, the first node should use BET interface and the second node will be a DataSink. Test two methods of connecting the nodes and check the content of the output directory.
# write your solution here
from nipype import Node, Workflow
from nipype.interfaces.io import DataSink
from nipype.interfaces.fsl import BET
# Skullstrip process
ex1_skullstrip = Node(BET(mask=True), name="ex1_skullstrip")
ex1_skullstrip.inputs.in_file = "/data/ds000114/sub-01/ses-test/anat/sub-01_ses-test_T1w.nii.gz"
# Create DataSink node
ex1_sinker = Node(DataSink(), name='ex1_sinker')
ex1_sinker.inputs.base_directory = '/output/working_dir/ex1_output'
# and a workflow
ex1_wf = Workflow(name="ex1", base_dir = '/output/working_dir')
# let's try the first method of connecting the BET node to the DataSink node
ex1_wf.connect([(ex1_skullstrip, ex1_sinker, [('mask_file', 'mask_file'),
('out_file', 'out_file')]),
])
ex1_wf.run()
# and we can check our sinker directory
! tree /output/working_dir/ex1_output
# now we can try the other method of connecting the node to DataSink
ex1_wf.connect([(ex1_skullstrip, ex1_sinker, [('mask_file', 'bet.@mask_file'),
('out_file', 'bet.@out_file')]),
])
ex1_wf.run()
# and check the content of the output directory (you should see a new `bet` subdirectory with both files)
! tree /output/working_dir/ex1_output