Important
This guide hasn’t been updated since January 2017 and is based on an older version of Nipype. The code in this guide is not tested against newer Nipype versions and might not work anymore. For a newer, more up to date and better introduction to Nipype, please check out the the Nipype Tutorial.
Nipype (Neuroimaging in Python - Pipelines and Interfaces) is an open-source, user-friendly, community-developed software package under the umbrella of NiPy. Nipype allows you to pipeline your neuroimaging workflow in an intuitive way and enables you to use the software packages and algorithms you want to use, regardless their programing language. This is possible because Nipype provides an uniform interface to many existing neuroimaging processing and analysis packages like SPM, FreeSurfer, FSL, AFNI, ANTS, Camino, MRtrix, Slicer, MNE and many more.
Nipype allows you to easily combine all those heterogeneous software packages whithin a single workflow. This procedure gives you the opportunity to pick the best algorithm there is for the problem at hand and therefore allows you to profit from the advantages of any software package you like.
Nipype is written in Python, an easy to learn and very intuitive programming language. This means that your whole neuroimaging analysis can be easily specified using python scripts. It won’t even take as many lines of code as you might fear. Nipype is very straightforward and easy to learn. As you will see, it is quite simple to combine processing steps using different software packages. Steps from previous analyses can be reused effortlessly and new approaches can be applied much faster.
You’re still concerned because you want to combine your own bash, MATLAB, R or Python scripts with Nipype? No problem! Even the creation of your own interface to your own software solution is straightforward and can be done in a rather short time. Thanks to Github, there’s also always a community standing behind you.
Nipype provides an environment that encourages interactive exploration of algorithms. It allows you to make your research easily reproducible and lets you share your code with the community.
Let’s assume you want to do an Analysis that uses AFNI for the Motion Correction, FreeSurfer for the Coregistration, ANTS for the Normalization, FSL for the Smoothing, Nipype for the Model Specification, SPM for the Model Estimation and SPM for the Statistical Inference. Normally this would be a hell of a mess. Switching between multiple scripts in different programming languages with a lot of manual intervention. On top of all that, you want to do your analysis on multiple subjects, preferably as fast as possible, i.e., processing several subjects in parallel. With Nipype, this is no problem! You can do all this and much more.
To illustrate the straightforwardness of an Nipype workflow and show how simply it can be created, look at the following example. This figure shows you a simplification of the analysis workflow just outlined.
![strict digraph {
dataset[label="rawdata", shape=box3d,style=filled, color=black, colorscheme=greys7 fillcolor=2];
datastorage[label="output", shape=box3d,style=filled, color=black, colorscheme=greys7 fillcolor=2];
sub1[label="Subject1", style=filled, fillcolor="#E6E6FF"];
afni1[label="Motion Correction (AFNI) - Sub1", style=filled, fillcolor="#E6E6FF"];
coreg1[label="Coregistration (FreeSurfer) - Sub1", style=filled, fillcolor="#E6E6FF"];
norm1[label="Normalization (ANTS) - Sub1", style=filled, fillcolor="#E6E6FF"];
smooth1[label="Smoothing (FSL) - Sub1", style=filled, fillcolor="#E6E6FF"];
spec1[label="Model Specification (Nipype) - Sub1", style=filled, fillcolor="#E6E6FF"];
est1[label="Model Estimation (SPM) - Sub1", style=filled, fillcolor="#E6E6FF"];
stat1[label="Statistical Inference (SPM) - Sub1", style=filled, fillcolor="#E6E6FF"];
sub2[label="Subject2", style=filled, fillcolor="#FFE6E6"];
afni2[label="Motion Correction (AFNI) - Sub2", style=filled, fillcolor="#FFE6E6"];
coreg2[label="Coregistration (FreeSurfer) - Sub2", style=filled, fillcolor="#FFE6E6"];
norm2[label="Normalization (ANTS) - Sub2", style=filled, fillcolor="#FFE6E6"];
smooth2[label="Smoothing (FSL) - Sub2", style=filled, fillcolor="#FFE6E6"];
spec2[label="Model Specification (Nipype) - Sub2", style=filled, fillcolor="#FFE6E6"];
est2[label="Model Estimation (SPM) - Sub2", style=filled, fillcolor="#FFE6E6"];
stat2[label="Statistical Inference (SPM) - Sub2", style=filled, fillcolor="#FFE6E6"];
sub3[label="Subject3", style=filled, fillcolor="#E6FFE6"];
afni3[label="Motion Correction (AFNI) - Sub3", style=filled, fillcolor="#E6FFE6"];
coreg3[label="Coregistration (FreeSurfer) - Sub3", style=filled, fillcolor="#E6FFE6"];
norm3[label="Normalization (ANTS) - Sub3", style=filled, fillcolor="#E6FFE6"];
smooth3[label="Smoothing (FSL) - Sub3", style=filled, fillcolor="#E6FFE6"];
spec3[label="Model Specification (Nipype) - Sub3", style=filled, fillcolor="#E6FFE6"];
est3[label="Model Estimation (SPM) - Sub3", style=filled, fillcolor="#E6FFE6"];
stat3[label="Statistical Inference (SPM) - Sub3", style=filled, fillcolor="#E6FFE6"];
dataset -> sub1;
dataset -> sub2;
dataset -> sub3;
subgraph flow1 {
edge [color="#0000FF"];
sub1 -> afni1 -> coreg1 -> norm1 -> smooth1 -> spec1 -> est1 -> stat1;
}
subgraph flow2 {
edge [color="#FF0000"];
sub2 -> afni2 -> coreg2 -> norm2 -> smooth2 -> spec2 -> est2 -> stat2;
}
subgraph flow3 {
edge [color="#00A300"];
sub3 -> afni3 -> coreg3 -> norm3 -> smooth3 -> spec3 -> est3 -> stat3;
}
stat1 -> datastorage;
stat2 -> datastorage;
stat3 -> datastorage;
}](_images/graphviz-15f3e6984796a80f0e02d6da4a457b70ba79e8d4.png)
The code to create an Nipype workflow that specifies the steps illustrated in the figure above and can run all the steps would look something like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 | #Import modules
import nipype
import nipype.interfaces.afni as afni
import nipype.interfaces.freesurfer as fs
import nipype.interfaces.ants as ants
import nipype.interfaces.fsl as fsl
import nipype.interfaces.nipy as nipy
import nipype.interfaces.spm as spm
#Specify experiment specifc parameters
experiment_dir = '~/experiment_folder'
nameofsubjects = ['subject1','subject2','subject3']
#Where can the raw data be found?
grabber = nipype.DataGrabber()
grabber.inputs.base_directory = experiment_dir + '/data'
grabber.inputs.subject_id = nameofsubjects
#Where should the output data be stored at?
sink = nipype.DataSink()
sink.inputs.base_directory = experiment_dir + '/output_folder'
#Create a node for each step of the analysis
#Motion Correction (AFNI)
realign = afni.Retroicor()
#Coregistration (FreeSurfer)
coreg = fs.BBRegister()
#Normalization (ANTS)
normalize = ants.WarpTimeSeriesImageMultiTransform()
#Smoothing (FSL)
smooth = fsl.SUSAN()
smooth.inputs.fwhm = 6.0
#Model Specification (Nipype)
modelspec = nipype.SpecifyModel()
modelspec.inputs.input_units = 'secs'
modelspec.inputs.time_repetition = 2.5
modelspec.inputs.high_pass_filter_cutoff = 128.
#Model Estimation (SPM)
modelest = spm.EstimateModel()
#Contrast Estimation (SPM)
contrastest = spm.EstimateContrast()
cont1 = ['human_faces', [1 0 0]]
cont2 = ['animal_faces', [0 1 0]]
contrastest.inputs.contrasts = [cont1, cont2]
#Statistical Inference (SPM)
threshold = spm.Threshold()
threshold.inputs.use_fwe_correction = True
threshold.inputs.extent_fdr_p_threshold = 0.05
#Create a workflow to connect all those nodes
analysisflow = nipype.Workflow()
#Connect the nodes to each other
analysisflow.connect([(grabber -> realign ),
(realign -> coreg ),
(coreg -> normalize ),
(normalize -> smooth ),
(smooth -> modelspec ),
(modelspec -> modelest ),
(modelest -> contrastest),
(contrastest -> threshold ),
(threshold -> sink )
])
#Run the workflow in parallel
analysisflow.run(mode='parallel')
|
By using multicore processing, SGE, PBS, Torque, HTCondor, LSF or other plugins for parallel execution you will be able to reduce your computation time considerably. This means, that an analysis of 24 subjects where each takes one hour to process would normally take about one day, but it could be done on a single machine with eight processors in under about three hours.
Note
The code above is of course a shortened and simplified version of the real code. But it gives you a good idea of what the code would look like, and how straightforward and readable the programming of a neuroimaging pipeline with Nipype is.
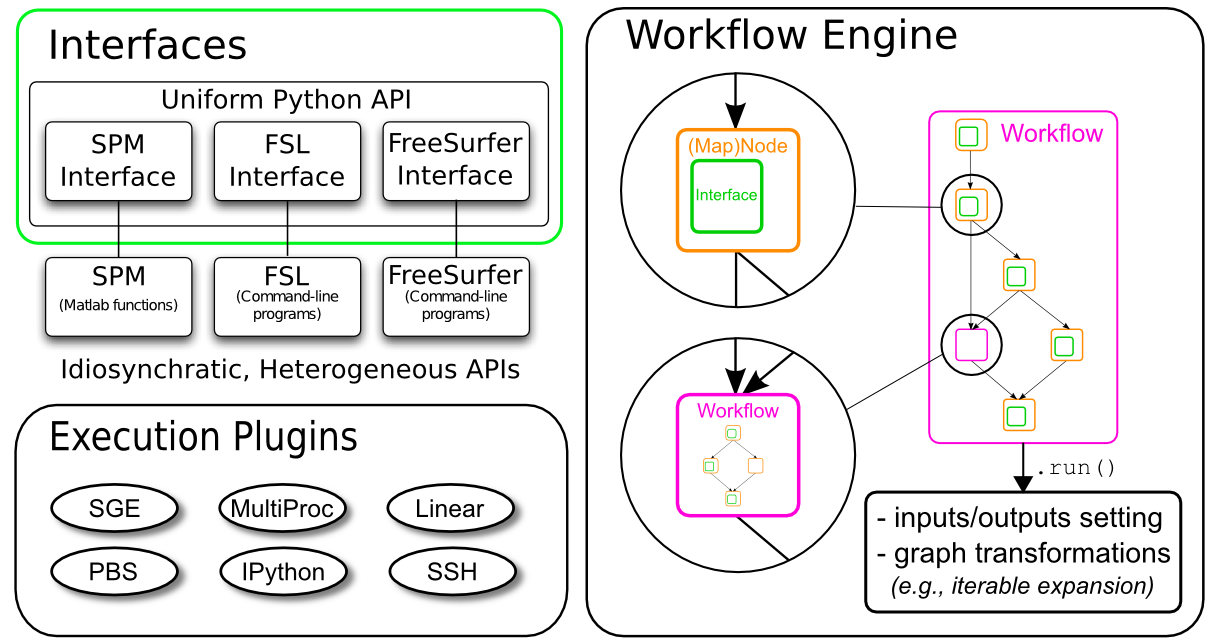
Nipype consists of many parts, but the most important ones are Interfaces, the Workflow Engine and the Execution Plugins.
Note
For a deeper understanding of Nipype go either to Nipype’s main homepage or read the official paper: Gorgolewski K, Burns CD, Madison C, Clark D, Halchenko YO, Waskom ML, Ghosh SS (2011) Nipype: a flexible, lightweight and extensible neuroimaging data processing framework in Python. Front. Neuroinform. 5:13. http://dx.doi.org/10.3389/fninf.2011.00013
Interfaces in the context of Nipype are program wrappers that enable Nipype, which runs in Python, to run a program or function in any other programming language. As a result, Python becomes the common denominator of all neuroimaging software packages and allows Nipype to easily connect them to each other. A short tutorial about interfaces can be found on the official homepage. More practical examples will be given later in this beginner’s guide.
For a full list of software interfaces supported by Nipype go here.
The core of Nipype’s architecture is the workflow engine. It consists of Nodes, MapNodes and Workflows, which can be interconnected in various ways.
Node: A node provides the information – parameters, filenames, etc. – that is needed by an interface to run the program properly for a particular job, whether as part of a workflow or separately.
MapNode: A Mapnode is quite similar to a Node, but it differs because it takes multiple inputs of a single type to create a single output. For example, it might specify multiple DICOM files to create one NIfTI file.
Workflow: A workflow (also called a pipeline), is a directed acyclic graph (DAG) or forest of graphs whose nodes are of type Node, MapNode or Workflow and whose edges (lines connecting nodes) represent data flow.
Each Node, MapNode or Workflow has (at least) one input field and (at least) one output field. Those fields specify the dataflow into and out of a Node, MapNode or Workflow. MapNodes use fields to specify multiple inputs (basically a list of input items). There they are called iterfields because the interface will iterate over the list of input items, and they have to be labeled as such to distinguish them from single-item fields.
A very cool feature of a Nipype workflow are so called iterables. Iterables allow you to run a given workflow or subgraph several times with changing input values. For example, if you want to run an analysis pipeline on multiple subjects or with an FWHM smoothing kernel of 4mm, 6mm, and 8mm. This can easily be achieved with iterables and additionally allows you to do this all in parallel (simultaneous execution), if requested.
Go to the documentation section of Nipype’s main homepage to read more about MapNode, iterfield, and iterables, JoinNode, synchronize and itersource and much more. Nonetheless, a more detailed explanation will be given in a later section of this beginner’s guide.
Note
For more practical and extended examples of Nipype concepts see Michael Waskom’s really cool Jupyter notebooks about Interfaces, Iteration and Workflows.
Plugins are components that describe how a workflow should be executed. They allow seamless execution across many architectures and make using parallel computation quite easy.
On a local machine, you can use the plugin Serial for a linear, or serial, execution of your workflow. If you machine has more than one core, you can use the Multicore plugin for parallel execution of your workflow. On a cluster, you have the option of using plugins for:
HTCondor
PBS, Torque, SGE, LSF (native and via IPython)
SSH (via IPython)
Soma Workflow
Note
Cluster operation often needs a special setup. You may wish to consult your cluster operators about which plugins are available.
To show how easily this can be done, the following code shows how to run a workflow with different plugins:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | # Normally calling run executes the workflow in series
workflow.run()
# But you can scale to parallel very easily.
# For example, to use multiple cores on your local machine
workflow.run('MultiProc', plugin_args={'n_procs': 4})
# or to other job managers
workflow.run('PBS', plugin_args={'qsub_args': '-q many'})
workflow.run('SGE', plugin_args={'qsub_args': '-q many'})
workflow.run('LSF', plugin_args={'qsub_args': '-q many'})
workflow.run('Condor')
workflow.run('IPython')
# or submit graphs as a whole
workflow.run('PBSGraph', plugin_args={'qsub_args': '-q many'})
workflow.run('SGEGraph', plugin_args={'qsub_args': '-q many'})
workflow.run('CondorDAGMan')
|
More about Plugins can be found on Nipype’s main homepage under Using Nipype Plugins.